
Diffusion model has already been used in computer vision for such a long time. However, in RSS 2023, it’s also used in Robotics, achieving a promising performance.

Diffusion Policy
Data
:arrow_forward: Original Data in HDF5 File
The official provides dataset in hdf5 format. The hdf5 file saves many stuffs of demonstrations, such as actions, dones(whether the episode is done), rewards, states(vectors describing the robot states), and obs. However, for training the policy, here just uses a part of this dataset.
Group: /data/demo_0
Dataset: /data/demo_0/actions shape: (127, 7)
Dataset: /data/demo_0/dones shape: (127,)
Dataset: /data/demo_0/rewards shape: (127,)
Dataset: /data/demo_0/states shape: (127, 45)
Group: /data/demo_0/next_obs
Dataset: /data/demo_0/next_obs/agentview_image shape: (127, 84, 84, 3)
Dataset: /data/demo_0/next_obs/object shape: (127, 14)
Dataset: /data/demo_0/next_obs/robot0_eef_pos shape: (127, 3)
Dataset: /data/demo_0/next_obs/robot0_eef_quat shape: (127, 4)
Dataset: /data/demo_0/next_obs/robot0_eef_vel_ang shape: (127, 3)
Dataset: /data/demo_0/next_obs/robot0_eef_vel_lin shape: (127, 3)
Dataset: /data/demo_0/next_obs/robot0_eye_in_hand_image shape: (127, 84, 84, 3)
Dataset: /data/demo_0/next_obs/robot0_gripper_qpos shape: (127, 2)
Dataset: /data/demo_0/next_obs/robot0_gripper_qvel shape: (127, 2)
Dataset: /data/demo_0/next_obs/robot0_joint_pos shape: (127, 7)
Dataset: /data/demo_0/next_obs/robot0_joint_pos_cos shape: (127, 7)
Dataset: /data/demo_0/next_obs/robot0_joint_pos_sin shape: (127, 7)
Dataset: /data/demo_0/next_obs/robot0_joint_vel shape: (127, 7)
Group: /data/demo_0/obs
Dataset: /data/demo_0/obs/agentview_image shape: (127, 84, 84, 3)
Dataset: /data/demo_0/obs/object shape: (127, 14)
Dataset: /data/demo_0/obs/robot0_eef_pos shape: (127, 3)
Dataset: /data/demo_0/obs/robot0_eef_quat shape: (127, 4)
Dataset: /data/demo_0/obs/robot0_eef_vel_ang shape: (127, 3)
Dataset: /data/demo_0/obs/robot0_eef_vel_lin shape: (127, 3)
Dataset: /data/demo_0/obs/robot0_eye_in_hand_image shape: (127, 84, 84, 3)
Dataset: /data/demo_0/obs/robot0_gripper_qpos shape: (127, 2)
Dataset: /data/demo_0/obs/robot0_gripper_qvel shape: (127, 2)
Dataset: /data/demo_0/obs/robot0_joint_pos shape: (127, 7)
Dataset: /data/demo_0/obs/robot0_joint_pos_cos shape: (127, 7)
Dataset: /data/demo_0/obs/robot0_joint_pos_sin shape: (127, 7)
Dataset: /data/demo_0/obs/robot0_joint_vel shape: (127, 7)
:arrow_forward: observation
Here observation includes an agent view image, a robot image from its hand, end effector’s positions and quaternion, and robot gripper positions.
agentview_image:
shape: [3, 84, 84]
type: rgb
robot0_eye_in_hand_image:
shape: [3, 84, 84]
type: rgb
robot0_eef_pos:
shape: [3]
# type default: low_dim
robot0_eef_quat:
shape: [4]
robot0_gripper_qpos:
shape: [2]
:arrow_forward: action
The first three dimension of action is to describe end effector’s position change, and the subsequent three dimension is to illustrate rotation change, and the last dimension is to record gripper’s status.
desired translation of EEF(3), desired delta rotation from current EEF(3), and opening and closing of the gripper fingers:
shape: [7]
HyperParameters
DDMP algorithm hyperparameters of policy, it can affect the denoising performance.
| name | definition | value |
|---|---|---|
| beta_start | the starting beta value of inference | 0.0001 |
| beta_end | the final beta value | 0.02 |
| beta_schedule | the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model | squaredcos_cap_v2 |
Task configuration of policy.
| name | definition | value |
|---|---|---|
| horizon | the step number of predicted action | 10 |
| n_action_steps | the step number of executing action | 8 |
| n_obs_steps | the step number of obs that the model prediction depends | 2 |
Image processing of policy
| name | definition | value |
|---|---|---|
| crop_shape | the target image dimension after cropping | 10 |
Hyperparameters of model(transformer) that the policy uses.
| name | definition | value |
|---|---|---|
| n_layer | the layer of decoder/encoder | 8 |
| n_head | head number of multi-head attention | 4 |
| n_emb | embedding dimension | 256 |
| p_drop_emb | drop prob of nn.Dropout before encoder/decoder | 0.0 |
| p_drop_attn | drop prob of nn.Dropout in transformer layer | 0.3 |
EMA parameters.
| name | definition | value |
|---|---|---|
| inv_gamma | inverse multiplicative factor of EMA warmup | 1.0 |
| power | exponential factor of EMA warup | 0.75 |
| min_value | the minimum EMA decay rate | 0.0 |
| max_value | the maximum EMA decay rate | 0.9999 |
dataloader:
| name | definition | value |
|---|---|---|
| batch_size | batch size | 64 |
| num_workers | number of processes when loading data | 8 |
optimizer:
| name | definition | value |
|---|---|---|
| transformer_weight_decay | transformer weight decay | 1.0e-3 |
| obs_encoder_weight_decay | obs encoder weight decay | 1.0e-6 |
| learning_rate | learning rate | 1.0e-4 |
| betas | decay rate of first-order moment and second-order moment | [0.9, 0.95] |
policy: # policy configuration
_target_: DiffusionTransformerHybridImagePolicy # policy type
shape_meta: # observations and actions specification
obs:
agentview_image:
shape: [3, 84, 84]
type: rgb
robot0_eye_in_hand_image:
shape: [3, 84, 84]
type: rgb
robot0_eef_pos:
shape: [3]
# type default: low_dim
robot0_eef_quat:
shape: [4]
robot0_gripper_qpos:
shape: [2]
action:
shape: [7]
noise_scheduler: # DDPM algorithm's hyperparameters
_target: DDPMScheduler # algorithm type
num_train_timesteps: 100
beta_start: 0.0001
beta_end: 0.02
beta_schedule: squaredcos_cap_v2
variance_type: fixed_small # Yilun's paper uses fixed_small_log instead, but easy to cause Nan
clip_sample: True # required when predict_epsilon=False
prediction_type: epsilon # or sample
# task cfg
horizon: 10 # dataset sequence length
n_action_steps: 8 # number of steps of action will be executed
n_obs_steps: 2 # the latest steps of observations data as input
num_inference_steps: 100
# image cfg
crop_shape: [76, 76] # images will be cropped into [76, 76]
obs_encoder_group_norm: False,
# arch
n_layer: 8 # transformer decoder/encoder layer number
n_cond_layers: 0 # >0: use transformer encoder for cond, otherwise use MLP
n_head: 4 # head number
n_emb: 256 # embedding dim (input dim --(emb)--> n_emb)
p_drop_emb: 0.0 # dropout prob (before encoder&decoder)
p_drop_attn: 0.3 # encoder_layer dropout prob
causal_attn: True # mask or not
time_as_cond: True # if false, use BERT like encoder only arch, time as input
obs_as_cond: True
# if ema is true
ema:
_target_: diffusion_policy.model.diffusion.ema_model.EMAModel
update_after_step: 0
inv_gamma: 1.0
power: 0.75
min_value: 0.0
max_value: 0.9999
dataloader:
batch_size: 64
num_workers: 8
shuffle: True
pin_memory: True
persistent_workers: False
val_dataloader:
batch_size: 64
num_workers: 8
shuffle: False
pin_memory: True
persistent_workers: False
optimizer:
transformer_weight_decay: 1.0e-3
obs_encoder_weight_decay: 1.0e-6
learning_rate: 1.0e-4
betas: [0.9, 0.95]
training:
device: "cuda:0"
seed: 42
debug: False
resume: True
# optimization
lr_scheduler: cosine
# Transformer needs LR warmup
lr_warmup_steps: 10
num_epochs: 100
gradient_accumulate_every: 1
# EMA destroys performance when used with BatchNorm
# replace BatchNorm with GroupNorm.
use_ema: True
# training loop control
# in epochs
rollout_every: 10
checkpoint_every: 10
val_every: 1
sample_every: 5
# steps per epoch
max_train_steps: null
max_val_steps: null
# misc
tqdm_interval_sec: 1.0
Training
obs:
agentview_image:
shape: [bs, T, 3, 84, 84]
type: rgb
robot0_eye_in_hand_image:
shape: [bs, T, 3, 84, 84]
type: rgb
robot0_eef_pos:
shape: [bs, T, 3]
robot0_eef_quat:
shape: [bs, T, 4]
robot0_gripper_qpos:
shape: [bs, T, 2]
action:
shape: [bs, T, 7]
timesteps:
shape: [1]
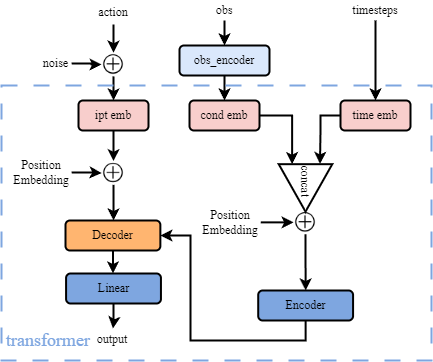
The picture above describes the overall structure of the training process. We need 3 types of inputs whose definition is introduced in the above code box. Before passing to transformer block, we do preprocessing, like adding noise to action, generating timesteps randomly, and using obs_encoder to extract features from observations.
""" 1. normalize obs & action -> nobs & naction """
nobs = self.normalizer.normalize(batch['obs'])
nactions = self.normalizer['action'].normalize(batch['action'])
trajectory = nactions
""" 2. take the subsequence of the first To in nobs and do feature extraction with obs_encoder """
# reshape B, T, ... to B*T
this_nobs = dict_apply(nobs, lambda x: x[:,:To,...].reshape(-1,*x.shape[2:]))
nobs_features = self.obs_encoder(this_nobs)
# reshape back to B, T, Do
cond = nobs_features.reshape(batch_size, To, -1)
""" 3. add noise to actions """
noise = torch.randn(trajectory.shape, device=trajectory.device)
# Add noise to the clean images according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_trajectory = self.noise_scheduler.add_noise(
trajectory, noise, timesteps)
""" 4. generate timesteps randomly """
bsz = trajectory.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0, self.noise_scheduler.config.num_train_timesteps,
(bsz,), device=trajectory.device
).long()
Step 2 can be explained in Visual Encoder.
Step 3 can be explained in Add Noise.
Visual Encoder (how obs_encoder extract features from obs)
In order to get cond, here has a obs_encoder to get features from observations, including images and robot states staff. The encoder is from robomimic package, which is a ObservationGroupEncoder class below. This class is designed to process multiple observations, so one of its arguments is observation_group_shapes, which describes shapes of every observation. And here lists one example of this.
"""
example of observation_group_shapes:
OrderedDict([('obs',
OrderedDict([
('agentview_image', [3, 84, 84]),
('robot0_eye_in_hand_image', [3, 84, 84]),
('robot0_eef_pos', [3]),
('robot0_eef_quat', [4]),
('robot0_gripper_qpos', [2])
]))])
"""
class ObservationsGroupEncoder(Module):
"""
This class allows networks to encode multiple observation dictionaries into a single flat, concatenated vector representation.
It does this by assigning each observation dictionary (observation group) an @ObservationEncoder Object.
This class takes a dictionary of dictionaries, @observation_group_shapes.
Each key corresponds to an observation group (e.g. 'obs', 'subgoal', 'goal')
and each OrderedDict should be a map between modalities and expected input shape (e.g. {'image': (3, 120, 160)})
"""
def __init__(
self,
observation_group_shapes,
feature_activation=nn.ReLU,
encoder_kwargs=None,):
"""
Args:
observation_group_shapes (OrderedDict): a dictionary of dictionaries.
Each key in this dictionary should specify an observation group,
and the value should be an OrderedDict that maps modalities to expected shapes.
feature_activation: non-linearity to apply after each obs net - defaults to ReLU.
encoder_kwargs (dict or None): If None, results in default encoder_kwargs being applied.
Otherwise, should be nested dictionary containing relevant per-modality information for encoder networks.
should be of form:
obs_modality1: dict
feature_dimension: int
core_class: str
core_kwargs: dict
...
...
obs_randomizer_class: str
obs_randomizer_kwargs: dict
...
...
obs_modality2: dict
...
"""
self.observation_group_shapes = observation_group_shapes
# create an observation encoder per observation group
Because it can process multiple observations, which means that it has multiple networks for different inputs. Here we have 5 observations, so we have 5 networks. Take agentview_image as an example, its network is established with backbone (resnet18) and pool layers. For such robot0_eef_pos low dimension observation, its network is None. Noticeably, every network here will turn the observation into a 2-dim vector, i.e. [batch_size, output_shape]. Finally, we concatenate all outputs in dim=1, so here is [batch_size, 64+64+3+4+2], i.e. [batch_size, 137].
ObservationEncoder(
Key(
name=agentview_image
shape=[3, 84, 84]
modality=rgb
randomizer=CropRandomizer(input_shape=[3, 84, 84], crop_size=[76, 76], num_crops=1)
net=VisualCore(
input_shape=[3, 76, 76]
output_shape=[64]
backbone_net=ResNet18Conv(input_channel=3, input_coord_conv=False)
pool_net=SpatialSoftmax(num_kp=32, temperature=1.0, noise=0.0)
)
sharing_from=None
)
Key(
name=robot0_eye_in_hand_image
shape=[3, 84, 84]
modality=rgb
randomizer=CropRandomizer(input_shape=[3, 84, 84], crop_size=[76, 76], num_crops=1)
net=VisualCore(
input_shape=[3, 76, 76]
output_shape=[64]
backbone_net=ResNet18Conv(input_channel=3, input_coord_conv=False)
pool_net=SpatialSoftmax(num_kp=32, temperature=1.0, noise=0.0)
)
sharing_from=None
)
Key(
name=robot0_eef_pos
shape=[3]
modality=low_dim
randomizer=None
net=None
sharing_from=None
)
Key(
name=robot0_eef_quat
shape=[4]
modality=low_dim
randomizer=None
net=None
sharing_from=None
)
Key(
name=robot0_gripper_qpos
shape=[2]
modality=low_dim
randomizer=None
net=None
sharing_from=None
)
output_shape=[137]
)
The Visual Encoder is not pre-trained model, it will be train with transformer at the same time.
Add Noise
The adding noise process can be computed through the formula below.
$x_t=\sqrt{\overline{\alpha_t}}x_0+\sqrt{1-\overline{\alpha_t}}\epsilon$
$x_0$ is the original sample, $\epsilon$ is the noise. $\beta_t $ is the forward process variances of timestep $t$. And it has $\alpha_t=1-\beta_t$. So the add_noise function can be displayed below.
def add_noise(original_samples, noise, timesteps):
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
noise_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noise_samples
Transformer
Transformer based on diffusion policy is actually one noise predictor. Take in noised data with some conditions, it can predict the noise in the data, and then restore its original data.
The transformer can be seen in the blue dash box in the picture above. After data preprocessing, we have noised sample/actions, obs_features/cond, and timesteps generated randomly as inputs.
Inputs:
sampleis a sequence of noised actions.conddenotes the observation feature.timestepsis the number of diffusion steps.
Encoder is designed to encode observation features and timesteps. n_cond_layers is a hyperparameter that can be set in configuration files, and if it’s > 0, the transformer encoder will replace MLP encoder.
Decoder takes in noised actions and encoded information, then predicts a noise with the same shape of X/sample as output.
Both transformer encoder and decoder are using torch.nn module, and the transformer forward computation is shown in the code box below.
Its structure is based on minGPT, which is decoder-only. Here it means that the input
sample(noised actions) will only being processed by the transformer decoder, which means that it does not need to learning information fromsampleby encoder, conversely it just needs to do the noise prediction task by decoder. Details are below, encoder is to processcondandtimesteponly, and decoder is to processsampleonly.
"""
input arguments:
sample: A sequence of noised actions.
cond: Observation features.
timesteps: diffusion step.
"""
# 1. inputs embedding
time_emb = self.time_emb(timesteps)
input_emb = self.input_emb(sample)
cond_obs_emb = self.cond_obs_emb(cond)
# 2. prepare transformer encoder inputs, including concatenating and adding position embeddings.
cond_embeddings = torch.cat([time_emb, cond_obs_emb], dim=1)
tc = cond_embeddings.shape[1]
position_embeddings = self.cond_pos_emb[
:, :tc, :
] # each position maps to a (learnable) vector
x = self.drop(cond_embeddings + position_embeddings)
# 3. process encoder inputs by encoder
x = self.encoder(x)
memory = x
# 4. prepare decoder inputs - embedded sample + position embedding
token_embeddings = input_emb
t = token_embeddings.shape[1]
position_embeddings = self.pos_emb[
:, :t, :
] # each position maps to a (learnable) vector
x = self.drop(token_embeddings + position_embeddings)
# 5. using preprocessed sample and condition information to predict noise by decoder
x = self.decoder(
tgt=x,
memory=memory,
tgt_mask=self.mask,
memory_mask=self.memory_mask
)
Loss Function
The training loss is below, the goal is to train a policy $\epsilon_{\theta}$ to predict noise accurately:
$Loss = MSE(\epsilon^k, \epsilon_{\theta}(O_t, A_t^0+\epsilon^k,k))$
where $\epsilon^k$ is a random noise with appropriate variance for iteration k. $O_t$ is the observation features.
After predicting noise by transformer, we got pred_noise. Then we use it to calculate training loss with the formula above.
# 1. Predict the noise residual
pred_noise = self.model(noisy_trajectory, timesteps, cond)
# 2. calculate training loss
loss = F.mse_loss(pred, target, reduction='none')
loss = loss * loss_mask.type(loss.dtype)
loss = reduce(loss, 'b ... -> b (...)', 'mean')
loss = loss.mean()y
Inference
After we got a trained policy $\epsilon_{\theta}$. We use the following formula to inference.
$A_t^{k-1}=\alpha(A_t^k-\gamma\epsilon_{\theta}(O_t,A_t^k,k)+N(0,\sigma^2I))$
When doing inference/testing/rollout, it will use predict_action function of policy in env_runner. The difference between inference and training is that, it would not do backward to update parameters, secondly instead of just getting noise to compute loss, it uses noise_scheduler.step to acquire the original trajectory.
First, we introduce how env_runner works. We can simply decompose the simulation process into 2 steps, i.e. running policy to get predicted actions and stepping environment with predicted actions.
Further,
env_runneruses multiprocessing to achieve multiple environment to execute parallelly. And these simulation environments have 2 types - train and test. Here train type means the initial state is from original dataset, and test type means initial state is set randomly with a different seed.
while not done:
# run policy
with torch.no_grad():
action_dict = policy.predict_action(obs_dict)
# step env
env_action = action
if self.abs_action:
env_action = self.undo_transform_action(action)
obs, reward, done, info = env.step(env_action)
done = np.all(done)
past_action = action
Below is the details of how to implement predicting actions.
# 1. randomly generate a trajectory.
trajectory = torch.randn(
size=condition_data.shape,
dtype=condition_data.dtype,
device=condition_data.device,
generator=generator)
# 2. set step values
scheduler.set_timesteps(self.num_inference_steps)
# 3. use scheduler.step to get original trajectory in a loop
for t in scheduler.timesteps:
# predict noise
model_output = model(trajectory, t, cond)
# compute previous image: x_t -> x_t-1
trajectory = scheduler.step(
model_output, t, trajectory,
generator=generator,
**kwargs
).prev_sample
# finally we get trajectory_0
Here is the algorithm of noise_scheduler.step. (x_t -> x_t-1)
# 1. compute alphas, betas
# 2. compute predicted original sample from predicted noise also called
# 3. Clip "predicted x_0"
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
# 5. Compute predicted previous sample µ_t
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
# 6. Add noise
pred_prev_sample = pred_prev_sample + variance
Issues on Different Ways of Passing Observations
We know that observation features is a input of transformer, but actually it has 2 ways to pass observation features.
Regard Observations as Condition
This way means that, the observation features will be processed by transformer encoder first. Then pass it as conditions to decoder for noise prediction.
cond = None
trajectory = nactions
# reshape B, T, ... to B*T
this_nobs = dict_apply(nobs, lambda x: x[:,:To,...].reshape(-1,*x.shape[2:]))
nobs_features = self.obs_encoder(this_nobs)
# reshape back to B, To, Do
cond = nobs_features.reshape(batch_size, To, -1)
Another way means that it would not pass the observation features to transformer encoder. Instead, it will regard the observation features as a part of sample. Here, we know that cond is set None, which proves that observation features are not passed to transformer encoder.
cond = None
trajectory = nactions
# reshape B, T, ... to B*T
this_nobs = dict_apply(nobs, lambda x: x.reshape(-1, *x.shape[2:]))
nobs_features = self.obs_encoder(this_nobs)
# reshape back to B, T, Do
nobs_features = nobs_features.reshape(batch_size, horizon, -1)
trajectory = torch.cat([nactions, nobs_features], dim=-1).detach()
Here is my point. Looking back ACT model structure, we regard it as a conditional VAE because it not only uses latent code from ENCODER to generate, it also uses observations (camera images, joint positions/torques). We regard these observations as conditions, because they are all processed by transformer encoder, and then are passed to transformer decoder to impact its decoding process. So the second passing observation way here, may cannot regard observation as conditions.
However, the point of the second way, I guess, is to make the model not just to predict noise of actions, but also predict noise of observations, i.e. restoring actions and observations at the same time. It’s like only such observations, we do such specific actions. To some extent, the actions are connected to observations.
Comments
- Specify the values of alpha, gamma in the denoising process.
gamma is the learning rate. alpha is a weight to denote the importance of noise.
- Specify the value of the variance for iteration k (with explanation).
# first sample a variance noise
variance_noise = torch.randn(model_output.shape, dtype=model_output.dtype, generator=generator)
# use _get_variance to get variance of timestep k
variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * self.betas[t]
variance = torch.clamp(variance, min=1e-20)
# finally do
variance = (self._get_variance(t, predicted_variance=predicted_variance) ** 0.5) * variance_noise
- The Visual Encoder is missing. Add it before the diffusion transformer.
done, see obs_encoder
- The diffusion transformer adopts the architecture from the minGPT (check it out), which is a decoder-only variant of the Transformer. Modify the content accordingly.
See Forward Details
- noised action = noised action execution sequence?
No, the shape of noised action is (B, T, Da), but the shape of noised action execution sequence is (B, n_action_steps, Da). Noticeably, T >= n_action_steps
- What is the format of the observation feature?
First, we take the subsequence of the first To observations and reshape it, and the make it processed by obs_encoder to get nobs_features, finally we do
nobs_features.reshape(B, To, -1)to reshape obs features.
- What is bs in [bs, horizon, action_dim]? Why the dimension has three situations?
bs means batch_size. Because it needs to consider whether regarding observations as a condition. If no, the shape of the output is like (B, T, Da+Do), which uses impainting method to replace action with obs features. If yes, then consider whether predicting action steps only, output shape is (B, n_action_steps, Da) when predicting action steps only, else (B, T, Da).